Je crois que ce sujet est dans le top 10 des trucs qui paraissent mystiques même après avoir passé des heures sur les docs sur le net. Et si ça prend effectivement un peu de temps CPU neuronale pour s’en sortir, on est loin de la montagne qu’on s’en est fait.
Scénario: vous avez écrit une lib. Elle est belle, elle sent bon le sable chaud. Vous voulez la partager.
La première étape, c’est de créer une fichier setup.py qui permettra aux gens de l’installer. La seconde, c’est de la mettre en ligne sur le site Pypi pour que les gens puissent l’installer avec pip.
Nous allons donc créer un setup.py pour une lib incroyable: la “sm_lib”.
Arborescence
Généralement, quand on développe une petite lib au fil de l’eau, on a une forte tendance à tout mettre en vrac dans un dossier. Cependant pour créer un paquet installable, il est beaucoup plus simple et propre d’avoir une organisation de fichiers standards. On peut faire sans, mais c’est prise de tête.
Prenons notre lib exceptionnelle…
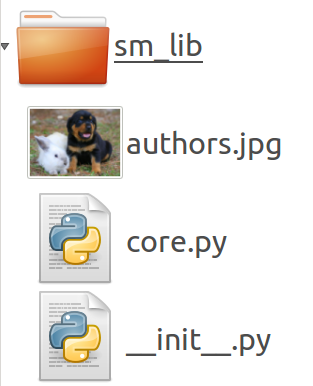
Pour le moment, elle est composée d’un dossier “sm_lib” avec 3 fichiers:
- une photo des auteurs (suite aux plaintes reçues, nous avons une nouvelle ligne de conduite concernant les photographies. Demain, les bébés !);
- l’indispensable __init__.py, qui est vide;
- un fichier core.py (qui peut avoir n’importe quel nom) qui contient le code de notre lib dont le but est de diffuser un message hautement subversif:
#!/usr/bin/env python # -*- coding: utf-8 -*- from datetime import datetime def proclamer(): print "[%s] Sam et Max, c'est bien" % datetime.now() if __name__ == "__main__": proclamer() |
Maintenant que nous avons changé de mentalité, nous voulons absolument propager notre nouveau message et ton du blog partout, donc on va distribuer cette bibliothèque.
Premièrement, on va réorganiser les fichiers et en rajouter quelques uns:
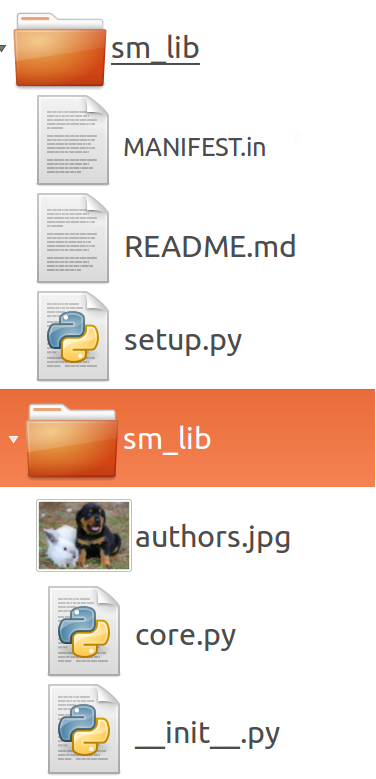
Vous noterez qu’on a mis notre dossier de lib, dans un autre dossier, et que les deux dossiers portent le même nom “sm_lib”. C’est redondant, mais c’est normal. Le dossier qui contient tout est le dossier de distribution, c’est l’emballage de notre lib. Le dossier qui contient notre code, c’est le dossier d’installation, c’est celui qui sera copié sur le système, et qui doit avoir un nom de package importable (uniquement des lettres et des _ dans le nom, ou un chiffre mais pas en premier caractère).
Les noms peuvent être différents, mais généralement on donne le même nom aux deux, car c’est plus simple.
On rajoute 3 fichiers:
- setup.py: un fichier de code Python qui est notre installeur.
- MANIFEST.in: un fichier texte qui liste les fichiers non Python qu’on inclura dans l’installation.
- README.md: un fichier markdown (c’est du texte, juste un peu formaté) contiendra une présentation du package.
Pour le moment nos trois fichiers sont vides.
Choix des outils
Une des difficultés principales dans la distribution d’un code Python, c’est l’abondance de solutions. Pour l’installeur, on peut choisir entre distribute, setuptools, distutils ou Distutils2.
Je vous passe les détails, mais j’ai essayé les 4. distutils est trop vieux. distribute va être remplacé par distutils2 qui lui est encore très jeune. La seule solution qui passe partout pour le moment c’est setuptools. Tarek Ziade va faire la gueule, mais c’est ce que je recommande d’utiliser pour le moment. Je metterai à jour cet article pour utiliser un setup.cfg et des moyens plus modernes quand tout ça sera devenu la solution de facto, mais je ne vais pas pousser à la migration.
Donc vous allez utiliser setuptools.
Ensuite on utilise un fichier MANIFEST.in pour lister les fichiers non Python. On pourrait tout passer en paramètres à la main, mais le manifeste est la solution la plus productive.
Enfin on utilise un fichier markdown. ReST est le standard en Python, mais il est compliqué (je me suis tapé suffisament de doc sphynx pour témoigner), et pas géré par Github par défaut. Markdown ressort bien sur Pypi même sans conversion en HTML, donc on va garder ce format.
Oh, et ça va sans dire, mais ça va mieux en le disant, on va distribuer les fichiers sous forme de source pure, pas sous forme d’exe ou d’egg. C’est installable avec pip sur toutes les plateformes, et ça évite bien des prises de tête.
Rendez votre paquets user friendly
La première chose à faire, avant de mettre en ligne, c’est de rendre votre paquets facile à utiliser. Assurez-vous d’avoir les docstrings qui vont bien, et faciliter les imports.
Par exemple, dans notre __init__.py, on va rajouter:
from core import proclamer |
Ainsi, l’utilisateur pourra faire:
from sm_lib import proclamer |
au lieu de :
from sm_lib.core import proclamer |
Faites cela uniquement pour les fonctions et classes les plus utiles. C’est un détail, mais ça rend l’expérience plus agréable.
Ensuite, si l’utilisateur est dans son shell, il va utiliser l’autocompletion pour découvrir votre lib. Il va se balader, et spammer “tab” pour voir “ce qu’il y a dedans”.
Pour faciliter ce process, limitez ce qui est importable avec __all__:
#!/usr/bin/env python # -*- coding: utf-8 -*- from datetime import datetime __all__ = ['proclamer'] def proclamer(): print "[%s] Sam et Max, c'est bien" % datetime.now() if __name__ == "__main__": proclamer() |
Ainsi, seul proclamer() sera importable depuis le module core si quelqu’un fait un import *. En effet, en important datetime, vous l’insérer dans le namespace de core, et donc il sera importable en faisant from sm_lib.core import datetime, et il apparaîtra dans l’autocompletion. Ici ça parait dérisoire, mais sur les grosses libs, ça fait beaucoup de bruit.
__all__ est une liste strings qui contient les noms de tout ce qu’on autorise à importer depuis ce module. Utilisez le pour rendre votre API d’import propre comme la chatte de… comme un sous neuf pardon. Désolé, par encore habitué à parler la novlang. On s’y met. On s’y met.
Pour finir on met les docstrings qui vont bien:
- une dans __init__.py pour décrire le package;
- une au sommet de core.py pour décrire module;
- une dans
proclamer()pour décrire la fonction.
Ainsi l’utilisateur qui va installer votre lib s’y retrouvera très facilement en utilisant la fonction help(). Même sans doc et hors ligne.
__init__.py (on rajoute aussi l’en-tête d’encoding vu que la docstring contient des caractères non-ASCII):
#!/usr/bin/env python # -*- coding: utf-8 -*- """ Ce module proclame la bonne parole de sieurs Sam et Max. Puissent-t-ils retrouver une totale liberté de pensée cosmique vers un nouvel age reminiscent. """ __version__ = "0.0.1" from core import proclamer |
On a aussi rajouté la version, car il n’y a rien de plus chiant que d’avoir un bug sur une lib et de ne pas savoir de quelle version il s’agit. Il va falloir maintenir cette variable à jour.
Et core.py:
#!/usr/bin/env python # -*- coding: utf-8 -*- """ Implémentation de la proclamation de la bonne parole. Usage: >>> from sm_lib import proclamer >>> proclamer() """ from datetime import datetime __all__ = ['proclamer'] def proclamer(): """ Fonction de proclamation de la bonne parole. Aucun paramètre, et retourne None, car tout le monde say que "Ex nihilo nihil" """ print "[%s] Sam et Max, c'est bien" % datetime.now() if __name__ == "__main__": proclamer() |
Je vous passe le pamphlet sur les tests, c’est plusieurs articles rien que pour expliquer le pourquoi du comment. C’est mieux si vous en avez, mais si vous n’en avez pas, ne vous empêchez pas de publier, ça peut se rajouter au fur et à mesure.
Petite remarque en passant: je met toute la doc en français pour que vous compreniez le principe, mais si vous publiez un truc, je vous recommande chaudement de tout écrire en anglais de A à Z (variables, fonctions, modules, docstrings, comments, readme, doc, tests, etc). Sans quoi votre audience sera limitée au nombre de francophones qui programment, et en Python, et qui ont le niveau pour intéresser aux libs externes. Autant dire l’équivalent de l’audience ridicule de ce blog.
README
Dans le fichier README.md, qui est un fichier texte ordinnaire, assurez-vous de mettez les choses suivante:
- A quoi sert la lib.
- Comment l’installer.
- Un exempe concret d’utilisation.
- La licence d’utilisation.
- Un lien vers la doc si elle existe.
Nous allons mettre le texte au format markdown. C’est un format très simple qui a le double avantage d’être automatiquement transformé en HTML par Github, et qui est bien lisible même quand il reste brut, tel qu’il sera affiché sur Pypi.
Dans notre cas, README.md va ressembler à un mélange des docstrings, un peu amélioré:
SM Lib - Proclame la bonne parole de sieurs Sam et Max
========================================================
Ce module proclame la bonne parole de sieurs Sam et Max. Puissent-t-ils
retrouver une totale liberté de pensée cosmique vers un nouvel age
reminiscent.
Vous pouvez l'installer avec pip:
pip install sm_lib
Exemple d'usage:
>>> from sm_lib import proclamer
>>> proclamer()
Ce code est sous licence WTFPL.
MANIFEST.in
Le fichier va contenir une liste de tous les fichiers non Python qu’on veut inclure dans le package. Dans notre cas, la photo et le README.
include *.md recursive-include sm_lib *.jpg
La syntaxe est elle aussi très simple, et utilise la notation des globs “*”.
La première ligne dit d’inclure tout fichier dans le nom est “n’importe quoi”.md. Il va inclure le README.
La seconde ligne dit d’inclure récursivement tout fichier dans le dossier sm_lib et ses sous-dossiers qui est nommé “n’importe quoi”.jpg. Il va inclure notre photo.
On peut mettre plusieurs lignes, et plusieurs motifs sur chaque ligne. Il n’est donc pas rare de voir des fichiers qui ressemblent à ça:
include *.txt *.rst recursive-include dir1 *.txt *.rst recursive-include dir2 *.png *.jpg *.gif recursive-include dir2 *.css *.js *.coffee
Setup.py
C’est la partie difficile. Le fichier setup.py contient une fonction qui va magiquement installer votre lib, et il faut lui passer des paramètres et l’appeler. Le problème c’est que cette fonction compte 34 (à ma connaissance) arguments.
Vous pouvez mettre n’importe quel code Python dans le setup.py, mais généralement la fonction setup() suffit.
Je vais mettre dans ce setup.py les paramètres que vous utiliserez les plus souvent:
#!/usr/bin/env python # -*- coding: utf-8 -*- from setuptools import setup, find_packages # notez qu'on import la lib # donc assurez-vous que l'importe n'a pas d'effet de bord import sm_lib # Ceci n'est qu'un appel de fonction. Mais il est trèèèèèèèèèèès long # et il comporte beaucoup de paramètres setup( # le nom de votre bibliothèque, tel qu'il apparaitre sur pypi name='sm_lib', # la version du code version=sm_lib.__version__, # Liste les packages à insérer dans la distribution # plutôt que de le faire à la main, on utilise la foncton # find_packages() de setuptools qui va cherche tous les packages # python recursivement dans le dossier courant. # C'est pour cette raison que l'on a tout mis dans un seul dossier: # on peut ainsi utiliser cette fonction facilement packages=find_packages(), # votre pti nom author="Sam et Max", # Votre email, sachant qu'il sera publique visible, avec tous les risques # que ça implique. author_email="lesametlemax@gmail.com", # Une description courte description="Proclame la bonne parole de sieurs Sam et Max", # Une description longue, sera affichée pour présenter la lib # Généralement on dump le README ici long_description=open('README.md').read(), # Vous pouvez rajouter une liste de dépendances pour votre lib # et même préciser une version. A l'installation, Python essayera de # les télécharger et les installer. # # Ex: ["gunicorn", "docutils >= 0.3", "lxml==0.5a7"] # # Dans notre cas on en a pas besoin, donc je le commente, mais je le # laisse pour que vous sachiez que ça existe car c'est très utile. # install_requires= , # Active la prise en compte du fichier MANIFEST.in include_package_data=True, # Une url qui pointe vers la page officielle de votre lib url='http://github.com/sametmax/sm_lib', # Il est d'usage de mettre quelques metadata à propos de sa lib # Pour que les robots puissent facilement la classer. # La liste des marqueurs autorisées est longue: # https://pypi.python.org/pypi?%3Aaction=list_classifiers. # # Il n'y a pas vraiment de règle pour le contenu. Chacun fait un peu # comme il le sent. Il y en a qui ne mettent rien. classifiers=[ "Programming Language :: Python", "Development Status :: 1 - Planning", "License :: OSI Approved", "Natural Language :: French", "Operating System :: OS Independent", "Programming Language :: Python :: 2.7", "Topic :: Communications", ], # C'est un système de plugin, mais on s'en sert presque exclusivement # Pour créer des commandes, comme "django-admin". # Par exemple, si on veut créer la fabuleuse commande "proclame-sm", on # va faire pointer ce nom vers la fonction proclamer(). La commande sera # créé automatiquement. # La syntaxe est "nom-de-commande-a-creer = package.module:fonction". entry_points = { 'console_scripts': [ 'proclame-sm = sm_lib.core:proclamer', ], }, # A fournir uniquement si votre licence n'est pas listée dans "classifiers" # ce qui est notre cas license="WTFPL", # Il y a encore une chiée de paramètres possibles, mais avec ça vous # couvrez 90% des besoins ) |
Tester si tout marche bien
Si vous publiez du code, je vais partir du principe que vous utilisez au moins un virtualenv :-)
Donc, activez un environnement de test, et dans le dossier contenant setup.py, faites:
python setup.py install |
Normalement votre lib devrait s’insaller dans votre env proprement. Vous devriez pouvoir faire dans un shell Python:
>>> from sm_lib import proclamer >>> proclamer() [2012-11-16 13:06:58.128545] Sam et Max, c'est bien |
Et comme on a créé une commande, on doit aussi pouvoir faire depuis un terminal:
$ proclame-sm [2012-11-16 13:08:18.763732] Sam et Max, c'est bien |
Si vous regardez dans votre virtualenv, vous verrez que votre package a été ajouté. Sur ma machine il se trouve par exemple à ~/.virtualenvs/test/lib/python2.7/site-packages/sm_lib-0.0.1-py2.7.egg/sm_lib.
La photo doit-être dedans, ainsi que le code Python. La photo est un exemple important à comprendre et à faire marcher car c’est le manifeste que vous utiliserez pour tous les fichiers non Python: CSS, Javascript, Documentation, Images, Xml, Json, etc.
Publier sur Pypi
Cela va vous paraitre étonnant, mais tout le monde peut publier sur Pypi. Pourvu que le nom soit disponible, vous pouvez en fait uploader n’importe quoi. Même une lib de test comme celle-ci.
Entrez la commande (il faut avoir accès à internet):
$ python setup.py register
Ceci va inscrire votre lib dans leur listing. Et donnera une sortie qui ressemble à ça:
running register running egg_info writing sm_lib.egg-info/PKG-INFO writing top-level names to sm_lib.egg-info/top_level.txt writing dependency_links to sm_lib.egg-info/dependency_links.txt writing entry points to sm_lib.egg-info/entry_points.txt reading manifest file 'sm_lib.egg-info/SOURCES.txt' reading manifest template 'MANIFEST.in' writing manifest file 'sm_lib.egg-info/SOURCES.txt' running check We need to know who you are, so please choose either: 1. use your existing login, 2. register as a new user, 3. have the server generate a new password for you (and email it to you), or 4. quit Your selection [default 1]:
Choissisez 2. Il va vous permettre de créer un compte. Quand il vous demandera de sauvegarder vos identifiants pour un usage future, répondre oui vous permettra de ne pas rentrer votre mot de passe à chaque upload.
La prochaine fois vous pourrez choisir 1, puisque vous aurez un compte.
Si ça se coupe, relancez juste la commande. Le but étant d’obtenir ça:
Registering sm_lib to http://pypi.python.org/pypi Server response (200): OK
Ce qui signifie que votre lib est inscrite sur Pypi (et que donc le nom était disponible, sinon il vous enverra chier et vous avez plus qu’à renommer votre lib).
Puis, il faut créer une distribution source (sdist) et le mettre en ligne (upload):
python setup.py sdist upload |
Et voilà, votre lib est en ligne et installable avec pip !
Voici la page pypi, et la page gitub (ce qui n’a rien à voir, mais si vous voulez le code source…).
C’est finit. Si vous voulez uploader une nouvelle version de votre lib, il faut changer __version__ car Pypi n’accepte pas deux fois la même version.

Ben merci bibi ;-)
Pour une question posé hier, c’est une sacré réponse.
Surtout si c’est du from scratch sans brouillon qui attendait la publication. Auquel cas faudra quand même penser a vous accorder une petite pause (faites signe si vous passez par Toulouse je vous en paierai une).
Me reste plus qu’a me mettre au boulot.
Pour le README, j’utilise pour ma part le format ReST (reStructuredText) qui est effectivement le standard en Python.
La petite astuce pour que GitHub le parse correctement, c’est de nommer le fichier README.rst. (Ça ne marche pas si le fichier s’appelle simplement README.)
De cette manière, on peut avoir un joli README affiché en HTML à la fois sur GitHub et sur PyPI. Youpi !
@cyp: de rien. Ca faisait longtemps que je me disais qu’un article comme ça manquait.
@Ronan: Ahhhhh. Je viens d’apprendre un truc là. Bon, la prochaine fois j’utiliserai RST alors. Par contre c’est vrai que RST est vraiment relou à apprendre. Les liens hypertexts sont chiannnnnnnnnnnnnnts à taper.
Merci pour cet article.
En complément ça vaut le coup de se pencher sur buildout et virtualenv.
Les liens hypertexts sont chiannnnnnnnnnnnnnts à taper.WHAT ? Et il est où ce prosélytisme envers Sublime Text ?!! ;)
Déjà, 2 notations existent pour faire des liens.
La baveuse :
Et la circoncis :
Mais ce blog m’ayant converti à ST2, j’ai trouvé des extensions comme sublime-rst-completion pour taper mes titres/liens plus facilement.
J’ai même retravaillé l’outil pour supporter plus de titres :
{ "trigger": "t1_part", "contents" : "${1/./=/g}\n${1}\n${1/./=/g}\n\n" }, { "trigger": "t2_chapter", "contents" : "${1/./*/g}\n${1}\n${1/./*/g}\n\n" }, { "trigger": "t3_section", "contents" : "${1}\n${1/./=/g}\n\n" }, { "trigger": "t4_subsection", "contents" : "${1}\n${1/./-/g}\n\n" }, { "trigger": "italic", "contents": "*${1}*" }, { "trigger": "bold", "contents": "**${1}**" }, { "trigger": "literal", "contents": "``${1}``" },Plus qu’à valider le tout avec RstPreview pour un beau rendu dans son browser préféré :)
(Et pour ceux qui preferent Vim, je dois citer l’indispensable vim-rst-tables).
Bref, une fois les bons outils trouvés, Rst peut lui aussi être *facilement* utilisé par tout le monde ;)
Si un outil a besoin d’un autre outil pour devenir simple à utiliser, c’est qu’il n’est pas simple.
Dans ce cas Rst et Markdown sont complexes : je te met au défi de faire un tableau à 2 diensions dans ces 2 langages à la main …
Et puis c’est surtout une question de productivité pour le coup, les 2 étant quasi similaires à 2-3 exceptions près.
Un tableau dans n’importe quel format du monde est dur à faire.
D’abord merci pour ce tuto. Enfin un truc accessible sur le sujet.
Lorsque tu écris que dans le __init__.py, il faut mettre (version 1)
from core import proclamerCe ne serait pas plutôt (version 2)
from sm_lib.core import proclamer?J’ai peut être raté qqch, mais la version 2 fonctionne et pas la 1, chez moi. En regardant deux trois libs sur mon système (python 2.7 ou 3.3), je vois la version 2.
Sinon, j’ai plus qu’à aller appliquer ces bonnes pratiques dans mes codes. :)
Je vois que ça marche avec sm_lib. Je vais voir pourquoi ça n’a pas marché sur la mienne :/
from core import proclamermarchec car le fichier __init__.py et le fichier core.py sont dans le même dossier, et que ce dossier est dans le PYTHON_PATH.from sm_lib.core import proclamerpeut marcher, mais selon les cas, il peut aussi poser problème: conflit de nom, de path, trigerring d’imports non voulus, etc.Je préfère toujours utiliser l’import le plus court et direct possible.
Et
alors ? Cf le pep correspondant : http://www.python.org/dev/peps/pep-0328/
Concernant les package, dire que je me suis payé une bonne partie de tout ça en fouillant sur le net la semaine dernière… Vous avez un don pour expliquer les choses clairement, c’est génial !
;-)
from .core import proclamer
Pour anticiper le futur, on peut mettre au début de ses fichiers :
from __future__ import absolute_import
Un des intérêts d’utiliser systématiquement les imports absolus est d’éviter de masquer par inadvertance des modules de la bibliothèque standard. Ça peut arriver quand dans notre projet on ajoute par exemple un nouveau module “email.py”, “logging.py” ou encore “stat.py”, et tout d’un coup un autre bout de notre programme se met à nous balancer des ImportError…
Avec des imports absolus, pas de risque et pas d’ambiguité :
from __future__ import absolute_import
# bibliothèque standard
from email import Message
# mon module à moi
from monprojet.email import ma_fonction
C’est vrai qu’avec notre entêtement quasi systématique à éviter Python 3, on oublie ce genre de truc.
Merci à tous pour ces précisions :)
Salut,
Le tuto est cool mais petite précision pour éviter de mettre à jour ton lien sur les métadonnées du projet. La liste se trouve ici list classifiers
voilou
Et voilà j’ai pu sortir ma première petites contribution
http://pypi.python.org/pypi/mysqlrocket
https://github.com/cypx/mysqlrocket
Rien d’extraordinaire (vu mon niveau en Python…) mais ça remplace avantageusement l’ancien script bash que j’utilisais et c’est plus facile à déployer et plus portable (tant que python 2.7 est dispo…).
@Ronan Amicel
Merci, j’ai utilisé ReST, rien d’insurmontable et le rendu est bon sur les pypi comme github.
Un autre petit retour, par rapport au tuto.
Quel est l’interet d’importer la lib dans le setup.py?
Je l’avais fait aussi au début mais ça posait problème lors des déploiement à cause des dépendance de la lib (forcément si on essaye d’utiliser des dépendances avant que le packager les aient installés…).
Bref comme j’y voyais pas d’utilité j’ai viré l’import et ça marche bien mieux sans.
En l’occurence, on utilise
__version__défini dans la lib. Ca évite de l’avoir en deux endroits.Oups j’avais oublié ça, en plus c’est ce que je faisais aussi au début.
Mais même en essayant de ruser et en mettant les variables dans un fichiers séparé et en utilisant
from mysqlrocket.infos import __version__
J’avais toujours le même problème, au déploiement le module était initialisé avant que les dépendances (install_requires) soit installées et l’installation plantait.
D’ailleurs si quelqu’un à une solution ça m’économisera des copié/collé.
Il n’y a pas de solution générale à ce problème: ça dépend beaucoup de ton architecture. Parmis les solutions:
– faire des lazy imports
– avoir les dépendances embeded dans le projet en fallback
– refactoriser pour que les imports ne soient pas trigger par le __init__
– mettre la version dans un fichier texte et lire ce fichier texte à l’__init__
Tu peux préciser (ou filer un lien explicatif) ce que sont les lazy imports ? C’est ce truc là http://code.activestate.com/recipes/473888-lazy-module-imports/ ?
C’est ça. Un lazy object, quel qu’il soit, est un objet qui est défini tôt, mais charge vraiment tout le code à la première utilisation.
Utilisé sur les imports, cela permet de définir un module importé, mais de déléguer l’import réel à la première utilisation de ce module. On peut ainsi résoudre des problèmes de références circulaires, empêcher d’éxécuter du code quand quand on fait juste un import ou gagner en performance.
Il y a même des libs toutes faites pour ça:
http://peak.telecommunity.com/DevCenter/Importing
Ok mais pas glop pour le setup.py, je préfèrerais que ça reste simple et on ne peut pas importer de module externe.
Finalement je vais tout mettre dans un fichier python dédié que je parse avec execfile(), c’est ce que j’ai trouvé de plus simple.
Nan, importe juste pas ta lib, c’est plus simple. Duplique le contenu: ça prend 5 minutes de plus de mettre la version à jour dans les 2 endroits, mais c’est toujours plus simple que l’alternative.
Bientôt, avec le setup.cfg, on devrait avoir moins de problèmes de ce genre.
Petite astuce qui pourrait mériter un article supplémentaire : pour ceux qui ont des “lib” de tools éparpillées un peu partout, parce que par exemple vous êtes dans une grosse boite avec plusieurs équipe, et que chacune ne dev pas la même chose, mais ça peut vous arriver de piquer une lib d’une autre équipe, (on respire), il y a la notion de namespace.
Admettons que chaque équipe soit corporate, leur package “racine” est le nom de la boite, et seulement derrière, chaque package est un tools. Chaque équipe faisant ça, pour éviter d’écraser les packages, vous pouvez définir le nom de la boite comme étant un namespace package.
et dans le __init__.py du package “le_nom_de_la_boite” un petit
et voilà, ça fait des chocapic. Comme ça, tout le monde peut faire
pip install tools_team1pip install tools_team2
la 2e lib n’ira pas écraser la 1e.
Alors oui, il y a sûrement un petit côté palitif d’une drôle de politique de nommage des lib sûrement hérité du monde Java (ouch), mais ça a le mérite d’exister et de marcher :)
Je n’ai pas compris : au niveau du pip, il en fait quoi du namespace ?
Bonjour. Merci pour ce tuto très instructif.
J’ai quand même une question. Si je souhaite utiliser l’image (ou autres fichiers non python) dans mon code, comment dois-je procéder ?
Il faut lister les fichiers images dans MANIFEST.in.
C’était fait mais je ne sais pas comment les retrouver dans le code. Imaginons que j’ai un fichier texte. Comment faire pour le charger ?
Sinon y a pkgutil pour faire ça proprement. Ca marche aussi avec les zip du coup.
Merci beaucoup pour les précisions, ça fonctionne impec :)
Salut, et merci pour le tuto.
Je me posais la question, est-ce que le principe du setup.py tel que vous le faites peut être utilisé pour un programme de plus grande envergure, avec plusieurs fichiers/modules ? Un genre d’installateur pour en faire un paquet pour une distribution après.
Bien à vous.
Pour info, Distribute a été mergé dans setuptools en mars 2013 :
http://mail.python.org/pipermail/distutils-sig/2013-March/020126.html
http://pythonhosted.org/setuptools/merge.html
(Et pour Tarek : http://mail.python.org/pipermail/distutils-sig/2013-March/020144.html)
@Rififi: oui c’est même le but.
@kontre: faudrait tester une installation avec distribute sur un windows vierge, et pareil sous mac et nunux et voir si c’est aussi si c’est aussi simple. Là j’ai pas la foi.
Non, justement, setuptools va récupérer les améliorations de distribute, donc il est plutôt conseillé de rester sur setuptools, qui aura le meilleur des deux (on peut toujours rêver…).
J’arrive longtemps après la bataille, mais, super article :)
question conne : je mets un fichier settings.py dans sm_lib/sm_lib et dans core.py je fais import settings pour utiliser ma conf … quand j’installe le machin via python setup.py install, comment je fais pour que le settings.py de mon virtualenv soit pris en compte à la place de celui qu’attend de trouver core.py tout à coté de lui ?
ouais désolé j’arrive tard avec ma question à 2frs 6sous :)
Mais a priori, tu dois pas avoir de fichier settings.py dans ton virtualenv O_o
Salut les pythons de haut niveau, ce poste m’a plus appris sur les outils a utiliser concernant l’affichage du README et des autres outils de packaging que distutils dont je vient de lire le HOW-TO pour la première fois.
Ca vole haut ici et je suis un disciple de Tarek qui a écrit le meilleur bouquin pour débutants sur python 2.*.* je trouve.
J’ai atterrie ici par un lien car je cherche a poster un module sur PYPi qui est déjà distribuer par le biais de mon site.
En faite mon module n’est composer que d’un seule fichier et il faut que j’arrive a le packager correctement afin de l’uploader.
L’auteur est très didactique et sympa, je reviendrai voir les articles futures ici.
Merci et bravo a l’auteur qui ne rentre pas dans les détails mais définis plutôt des grandes lignes.
Biz a tarek, gloire à tarek, praise to tarek. Et to mozilla.
J’ai finalement réussi a créer un paquetage grâce a la fonction distutils.core.setup() qui en fait des choses, j’en ai profiter pour écrire un tutoriel minimal sur le sujet:
Uploader un paquetage sur PyPI grâce a au module distutils
J’espère que ça peut aider ceux a qui la doc du module distutils fait peur que j’invite a lire le
HOW-TO distutils.
Et merci pour l’info concernant le ReStructuredText dont je vous invite a lire:
-) la documentation
-) Le quickstart en français.
Afin de vous familiariser avec ce format.
@Morgotth, en Rst je sais pas mais en Markdown un tableau ça se déclare (environ) comme ça (indentation optionnelle) :
121122Et ça je le fait “à la main” quasiment à chaque projet =D
Mais la table et peut être un mauvais exemple pour un langage censé servir à mettre en forme du texte et pas spécialement des données.
Sinon, je ne poste pas ici juste parce que j’aime bien contredire les gens ou faire du “nécroposting” (même si sur un blog ça compte pas pour de vrai), mais pour savoir quels outils python vous utilisez pour parser un fichier markdown en python (pour enregistrer/afficher) et/ou javascript (pour du live preview).
C’est ma semaine “j’me ferais bien un peu de Markdown” et du coup je cherche des sources.
La preview des comm…
donc, je fait comme ça sans les espace:
<table><tr><td>1</td><td>2</td></tr><tr><td>3</td><td>4</td></tr></table>merci pour ce tuto, il m’a vraiment aidé durant mon stage de fin d’études.
Vraiment bien ton article, je vais aller regarder le reste …
Le 0bin du code est mort (404).
‘Voulez pas mettre directement l’URL officielle des classifiers https://pypi.python.org/pypi?%3Aaction=list_classifiers.
Ça me parait plus sain.
Je suis passé devant un package: https://pypi.python.org/pypi/twine
Et là je me suis dit: “Sam et Max m’ont fait transité mon mot de passe en clair ?” (surtout Sam en vrai :D)
Plus sérieusement, les communications avec PyPI sont actuellement en HTTP (sans le S),
Donc visible par tout les curieux.
The solution is : “Twine”, et ça vous apportera des trucs sympas en plus.
Twine est sorti en 2013, l’article date de 2012 (déjà ! :)). Faudra que je fasse une mise à jour.
Trois ans après, merci pour l’article qui m’a été super utile !
Et aussi une remarque au sujet de l’utilisation de all dans un module. Si ca restreint effectivement ce qui est importable avec un
from mymodule import *, ca ne semble pas trop aider pour ce qui est de la completion.Dans ipython, avec l’exemple du tuto, un
import coresuivi decore.TABpropose biencore.datetime core.proclamer.Bon en fait il y a moyen de restreindre la complétion de IPython à ce qui est présent dans all (voir ici )
Mais c’est qu’elle a du succès cette lib !
Downloads (All Versions):
2 downloads in the last day
20 downloads in the last week
50 downloads in the last month
Proclamons !
Je viens d’envoyer une lib et je constate que le rendu du fichier README.md est déguelasse. Je l’ai écrit avec le Bloc-note de windows, ce ne doit pas être la bonne façon de faire
Cool
La méthode par
python setup.py registerne fonctionne plus:Registering zesk06 to https://upload.pypi.org/legacy/
Server response (404): Not Found
Maintenant il semble obligatoire de passer par twine:
$ pip install twine
$ twine upload sdist/*.tar.gz -u USERNAME -p PASSWORD
Voila qui est interessant.
En effet, register ” is no longer supported” mais sdist upload fonctionne toujours. Il est donc possible de s’en tirer en rajoutant un fichier .pypirc dans $HOME et avec le contenu suivant :
[distutils]
index-servers =
pypi
[pypi]
repository: https://upload.pypi.org/legacy/
username: moi
Bonjour, et merci pour cet article ! Et pour votre site !
J’ai bien réussi à créér une petite lib test, et à l’installer avec setup.py… je ne suis pas encore allé jusqu’à la mettre sur pypi car je n’ai pas envie de polluer pypi avec une lib qui ne sert pas à grand chose, mais j’aurais deux questions à ce sujet:
peut on publier sur pypi que des lib (dans le sens “module” python) ou bien peut on s’en servir pour distribuer des programmes en python qui ne soient pas des modules au sens strict ?
j’ai un programme en python qui s’utilise en ligne de commande (j’ai fait ca avec argparse) ; quand je veux l’installer chez moi, je modifie les droits pour qu’il soit exécutable et je le place dans /usr/local/bin … et ca marche très bien. Mais je voudrais distribuer ce programme et qu’il puisse s’installer plus facilement. Du coup j’ai essayé de faire comme pour ma lib en suivant ce tuto, mais au final impossible d’installer le setup.py ! Je sais que le entry_point permet de créér des commandes, mais sans arguments, ce qui ne me convient pas… du coup, y’a -t -il une autre solution… ou bien suis je complètement a coté de la plaque, et setuptools n’est pas fait pour ca ?
Merci :-)
Les programmes cmd sont ok
Bonsoir, je viens de tenter de faire l’install de sm-lib via pip et j’ai eu l’erreur suivante :
Collecting sm_libUsing cached sm_lib-0.0.1.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "", line 1, in
File "C:\Users\ygnobl\AppData\Local\Temp\pip-build-wsia0zhr\sm-lib\setup.py", line 8, in
import sm_lib
File "C:\Users\ygnobl\AppData\Local\Temp\pip-build-wsia0zhr\sm-lib\sm_lib\__init__.py", line 12, in
from core import proclamer
ModuleNotFoundError: No module named 'core'
Command "python setup.py egg_info" failed with error code 1 in C:\Users\ygnobl\AppData\Local\Temp\pip-build-_dlgmx13\sm-lib\
Comme malgré l’heure je ne suis pas trop idiot, bien qu’étant sous windows, il s’agit de la réponse que j’eûs sur un terminal ouvert en admin, après l’avoir eue en utilisateur. Vu que j’ai déjà installé des modules pour bricoler, je me dis que l’info mérite d’être remontée.
Au passage, gros merci pour ce blog. Je m’autoforme à python en dilettante, et c’est une énorme (cmb) source d’infos pour essayer d’apprendre les bonnes manières.
C’est un vieil article valable uniquement pour Python 2 qu’il faudra un jour que j’update.
Salut les gars !
Vraiment fan de votre blog, ma principale source d’information pour tous les petits tips en python ;)
J’aimerais quelques précisions sur le
__all__: y a t il moyen de lui assigner automatiquement la liste des fonctions définies dans le fichier, et uniquement ceux là ? Ca me parait laborieux de devoir maintenir à jour cette liste à la main dans tous les fichiers d’un gros projet…Merci beaucoup !
Plusieurs choix:
créer un décorateur et l’appliquer à chaque fonction
créer une fonction qui parse locals(), et retourne une liste de fonctions en filtrant celles avec un différent chemin d’import
créer un import hook qui fait ça avec l’ast
Mais honnêtement all n’est utile que pour “*”, donc pas certain que ça vaille le coup de s’emmerder.